[Add link to repo]
Ever wondered how editing and searching for text in a file with > 10K lines of code in your favorite code editor (VSCode, Neovim etc.) is pretty quick. One of the key reasons why is because these editors rely on some data structures that provide efficient look up and editing capabilities, allowing you to work do your work faster. In this post, lets explore these data structures, write them from scratch, run a few benchmarks and hopefuly at the end understand them better.
I have been using the Zed code editor for a few months now. Its been amazing and I love it. Zed is open-source so I checked out their repo and blogs, and stumbled upon the blog post on Rope which is a data structure that powers Zed. That is the motivation of this blog, it led me to rabbit hole and as a result here we are.
Benchmark
Lets first start with a benchmark. This is help us understand the trade-offs of each of these data structures. The goal is simple, measure the time complexity of the following operations 1) insertion (anywhere in the file) 2) deletion (start and middle of the file) 3) random_access (anywhere in the file). I choose rust as the language, cause why not and the data structures we are looking to benchmark will implement the following trait
trait Editor {
fn insert(&mut self, key: String, pos: usize);
fn delete(&mut self, pos: usize, length: usize);
fn get_char(&self, index: usize) -> Option<char>;
}
- Insertion - We will insert some text to the data structure at random positions and measure the time taken for the insertion to complete
- Deletion - We remove 1000 characters at the beginging and middle of the text and measure the time.
- Random Access - Move to random character in the file
[Add benchmark code here, talk about what the different benchmark evaluates]
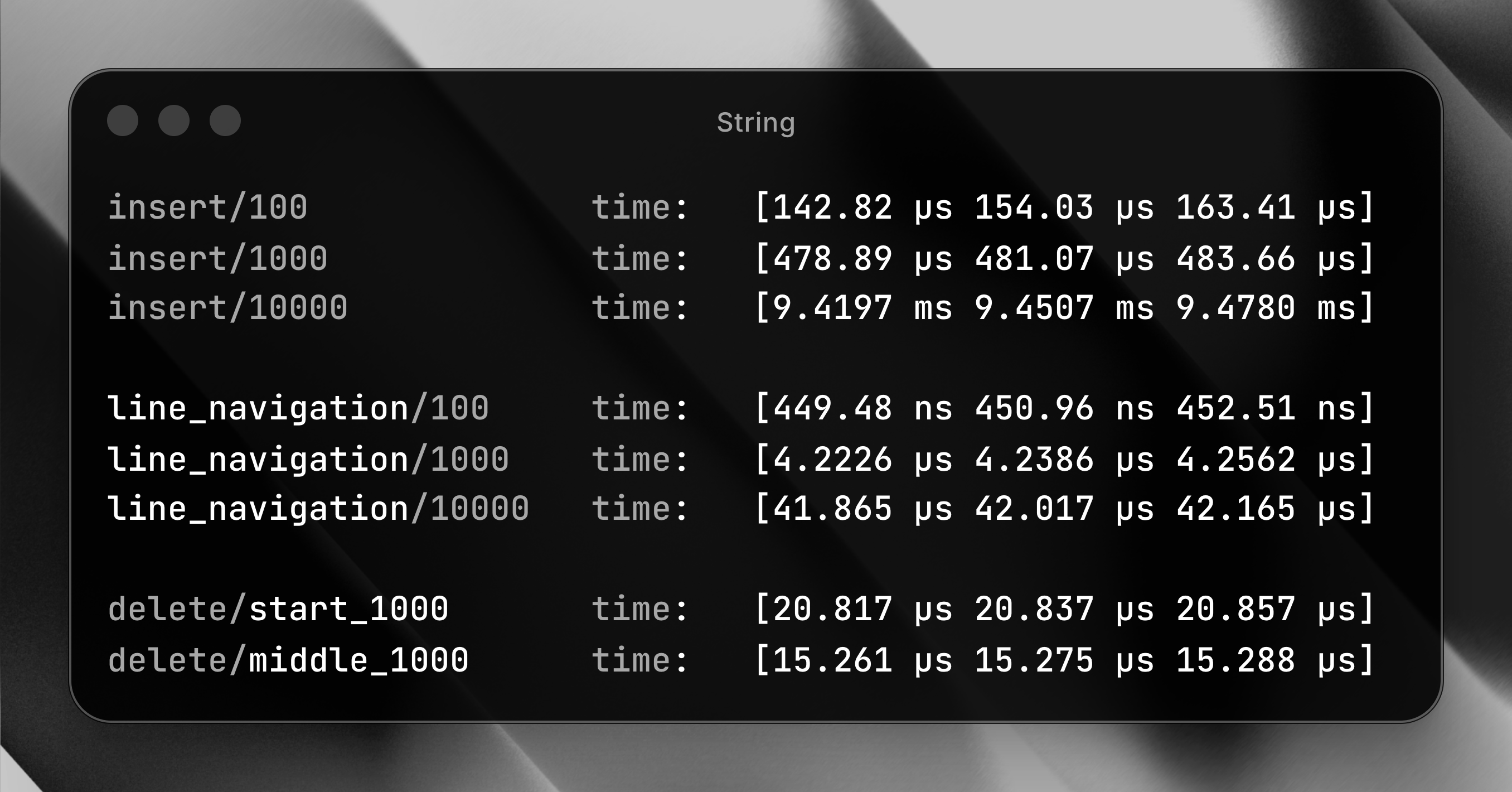
The numbers reported as part of the benchmark are run on an M4 pro Macbook pro.
Array of chars - a.k.a String
Probably the first data structure (and a naive one) to use is a String, i.e. store the contents of the editor as a continuous array of characters. A pretty simple one but has some downsides:
Insertion
Using a dynamic array of chars to store the contents of the file poses some problems during insertion. If you are appending to the end of file (or string in this case) and if there is enough space in the array, then your time complexity O(1). Howver, if the array is full, it requires another memory allocation (to read more about memory allocation, read this). Since re-allocation requires copying over all characters, its time complexity is O(n). However, since dynamic arrays usually double in size, the amortized complexity is still O(1) for insertion at the end.
Insertion in the beginging or the middle is always a O(n) operation since contents have to be moved over.
Deletion
Delete operations suffer from a similar problem as insertion. Deletion at the end is a constant time operation since there is no shifting of elements needed but deletion at the begining or middle is a O(n) operation since it requires the remaining elements to be shifted
Random Access
Random access is a O(1) operation here always because, if you have an index of the element you want to access you can use pointer arthimetic to quickly acccess that element
Checkout the code for String data structure based editor below
pub struct BasicString {
pub data: String,
}
impl BasicString {
pub fn new() -> Self {
Self {
data: String::from(""),
}
}
}
impl Editor for BasicString {
fn insert(&mut self, key: &str, pos: usize) {
let safe_pos = pos.min(self.data.len());
self.data.insert_str(safe_pos, key);
}
fn delete(&mut self, pos: usize, length: usize) {
let max_len = (pos + length).min(self.data.len());
self.data.replace_range(pos..max_len, "");
}
fn get_char(&self, index: usize) -> Option<char> {
self.data.chars().nth(index)
}
}
The following is the results of the benchmark